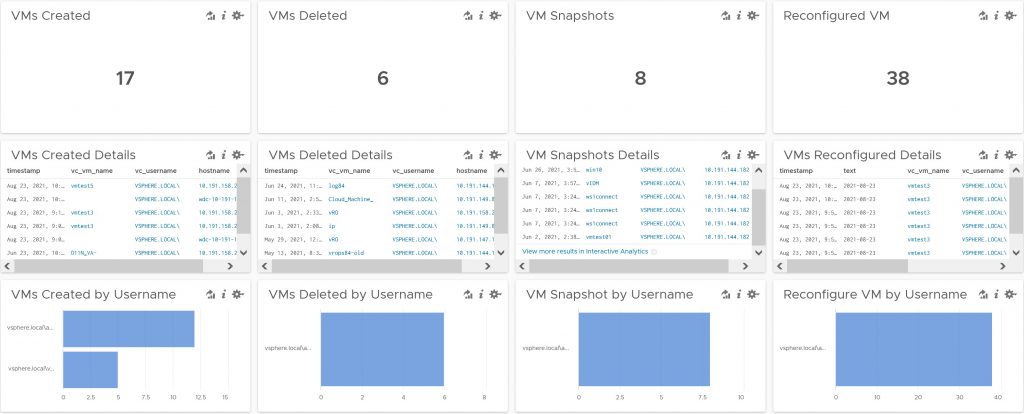
Log Insight – VM Monitoring Dashboard (Download)
This is a must-have dashboard for anyone who wants to know who did what with my Virtual Machines. With this […]
This is a must-have dashboard for anyone who wants to know who did what with my Virtual Machines. With this […]
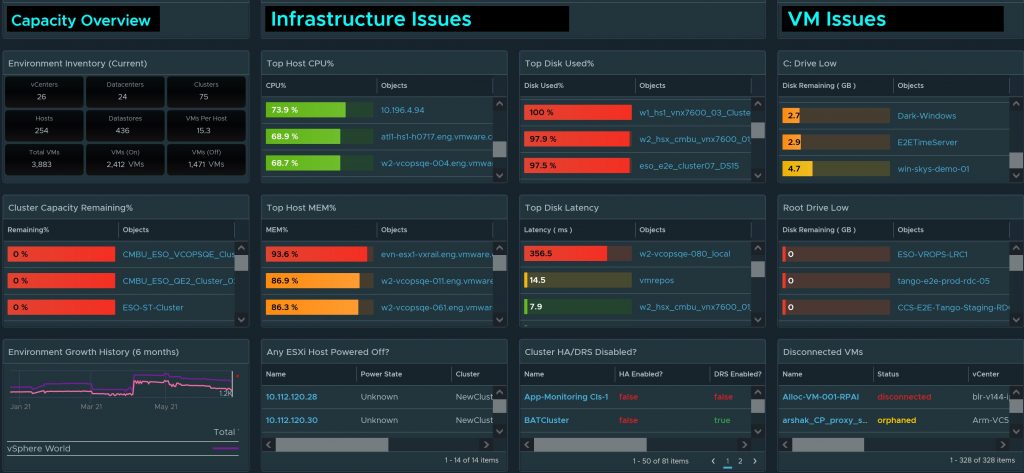
With the new features of 8.4, I was finally able to finish my Executive Dashboard the way I envisioned it.

In this post, I will answer how I personally handle alerting for my customers. Once you install an enterprise monitoring

Monitor the performance and configuration of the following appliances: vCenter Servers, NSX, NSX-T, vRA, vROPS, Log Insight, Orchestrator, Life Cycle
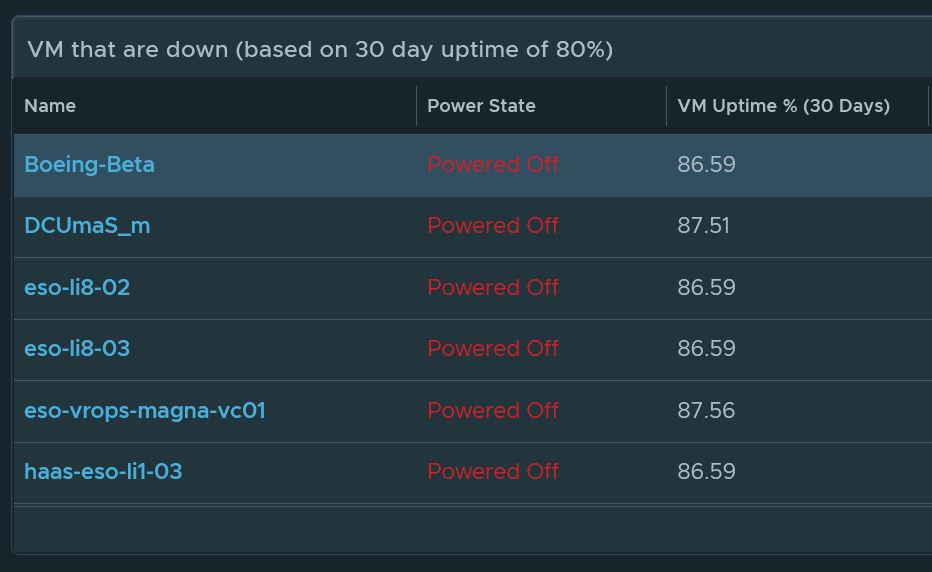
The VM uptime dashboard will keep track of any VMs that are currently down but has an uptime of more

Every time I walk into a new engagement with a Fortune 500 company, I always ask the customer the question
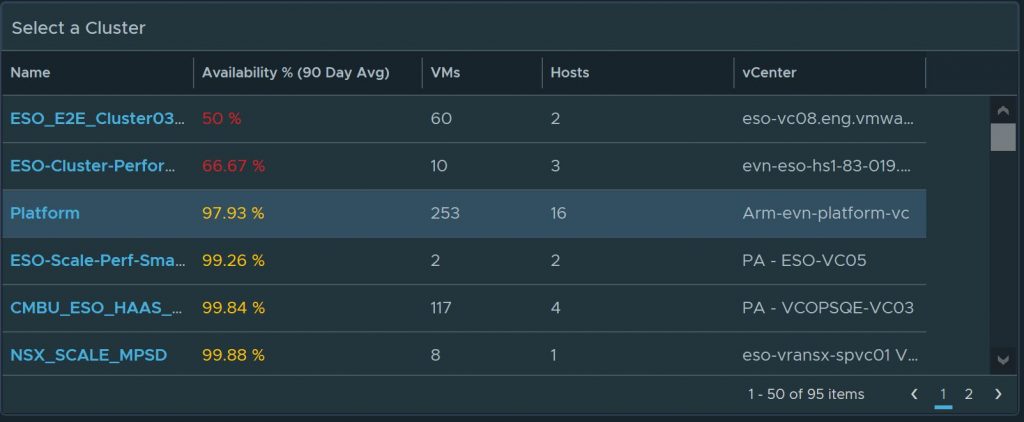
Management is always worrying about infrastructure uptime. They usually want to know if there were any unplanned outages in the
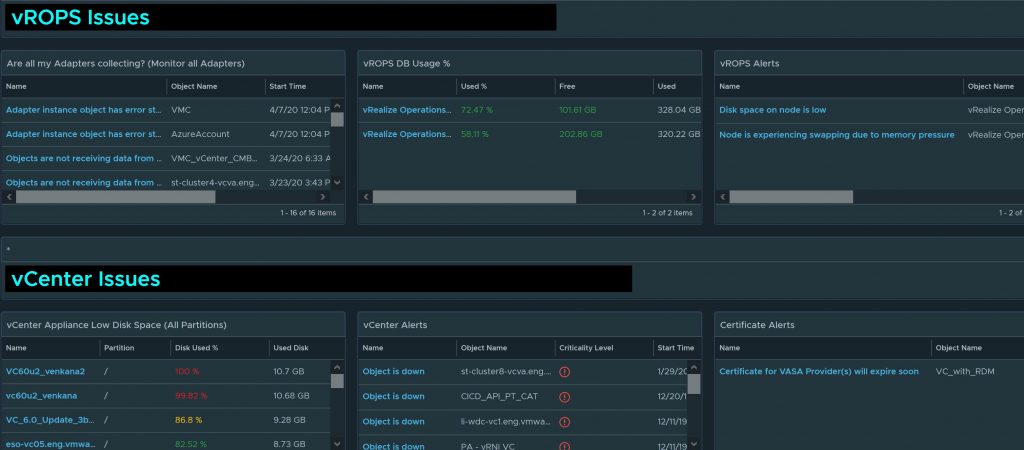
This is a must-have dashboard for those who wish to monitor vCenter Appliance partition disk space usage and vROPs disk

One click and you can analyze everything wrong with your current vCenter Environment! From physical hardware issues, VM performance and
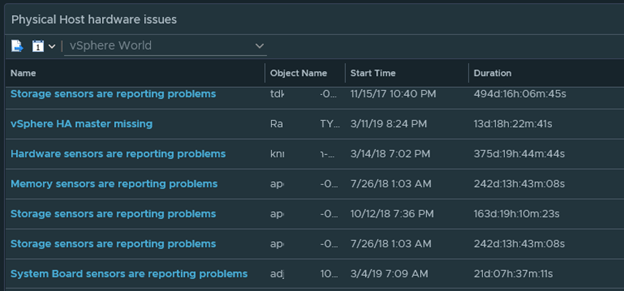
The purpose of this dashboard is to capture all the important issues with Physical Host Hardware, host network availability, storage
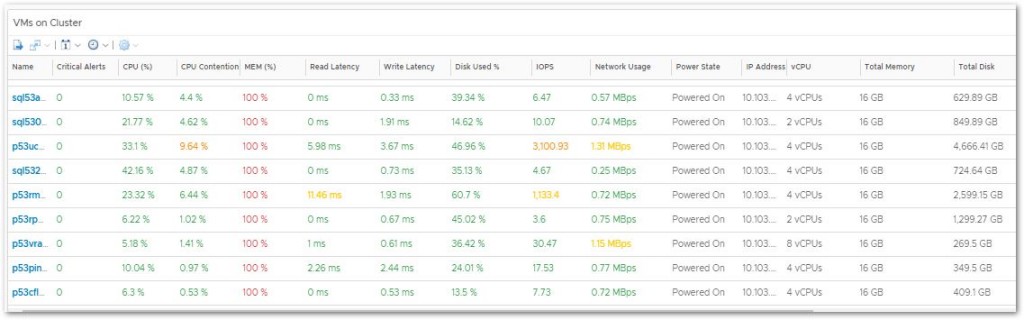
I don’t share out any advance dashboards on my blog, mainly because all my advances ones I keep exclusively to
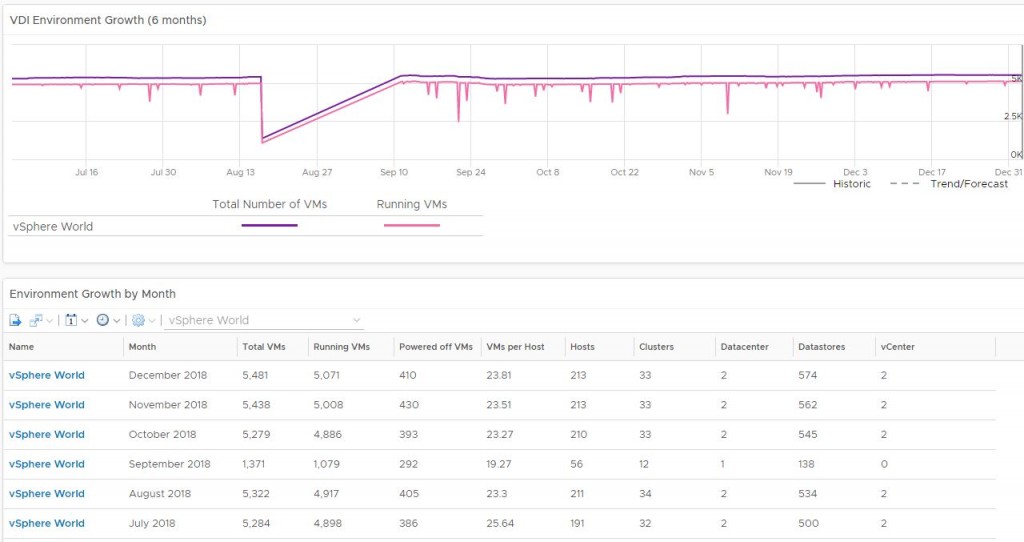
Here is my latest enhancement of the Environment Growth Dashboard. This dashboard allows Engineers, Operators, and Managers to view growth
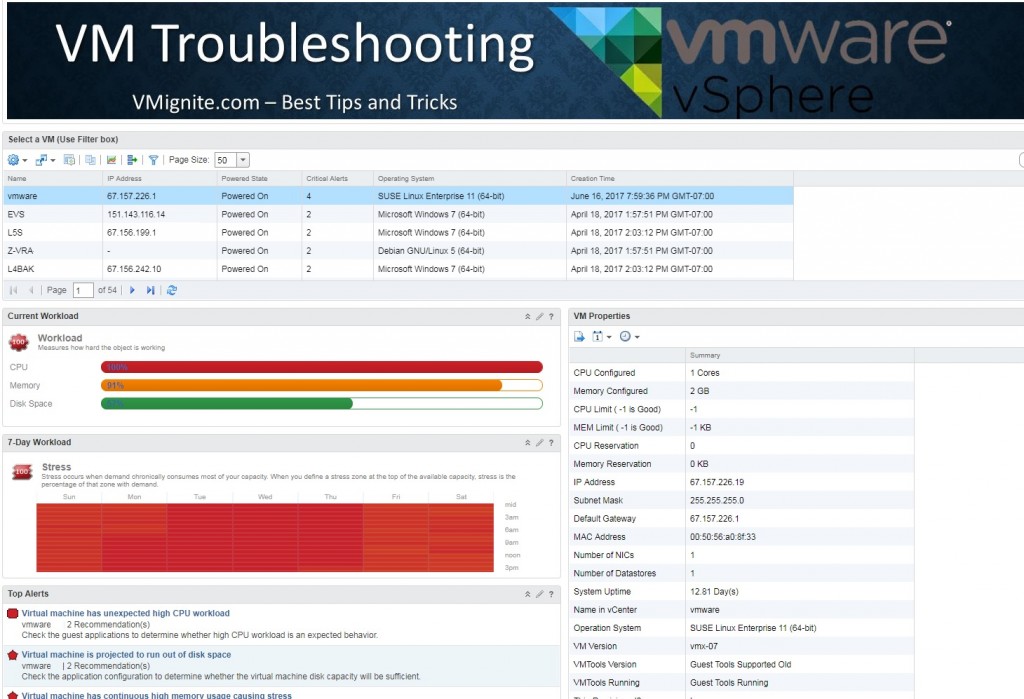
I have updated the VM Troubleshooting Dashboard for up to Version 7.0. This is a must-have dashboard for any environment
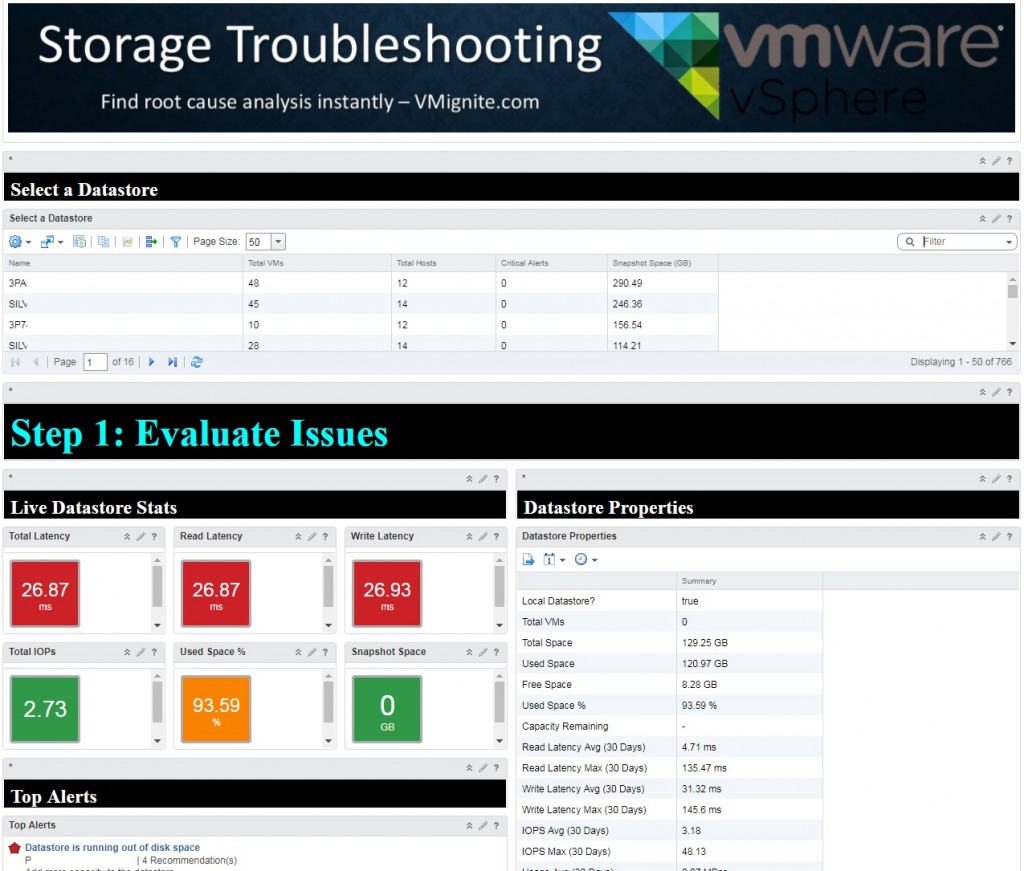
This is an updated version of my popular vROPS Datastore Troubleshooting Dashboard. I updated and enhanced my dashboard up to
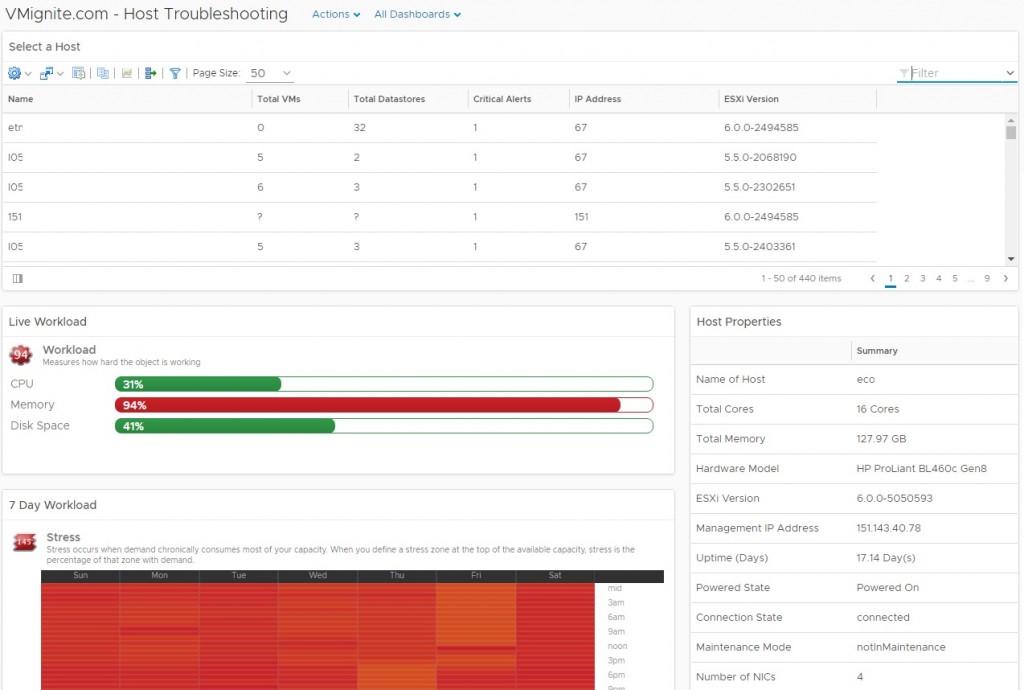
Here is the latest Host Troubleshooting dashboard that was enhanced and fixed up to the latest version of vROPs 7.0.