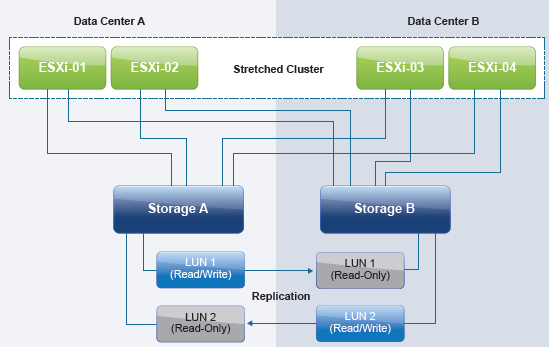
VMware vSphere® Metro Storage Cluster (vMSC) is a specific configuration within the VMware Hardware Compatibility List (HCL). These configurations are commonly referred to as stretched storage clusters or metro storage clusters and are implemented in environments where disaster and downtime avoidance is a key requirement. This best practices document was developed to provide additional insight and information for operation of a vMSC infrastructure in conjunction with VMware vSphere. This guide was created based on VMware vSphere 6 recommended best practices for Stretched Metro clusters which can be found here https://www.vmware.com/resources/techresources/10482
Configuring a new Stretch Cluster
vSphere HA Consideration
A full site failure is one scenario that must be taken into account in a resilient architecture. VMware recommends enabling vSphere HA admission control. Workload availability is the primary driver for most stretched cluster environments, so providing sufficient capacity for a full site failure is recommended. Such hosts are equally divided across both sites. To ensure that all workloads can be restarted by vSphere HA on just one site, configuring the admission control policy to 50 percent for both memory and CPU is recommended.
VMware recommends using a percentage-based policy because it offers the most flexibility and reduces operational overhead. Even when new hosts are introduced to the environment, there is no need to change the percentage and no risk of a skewed consolidation ratio due to possible use of VM-level reservations
-
Right click on your Datacenter and select New Cluster
-
Configure the New Cluster
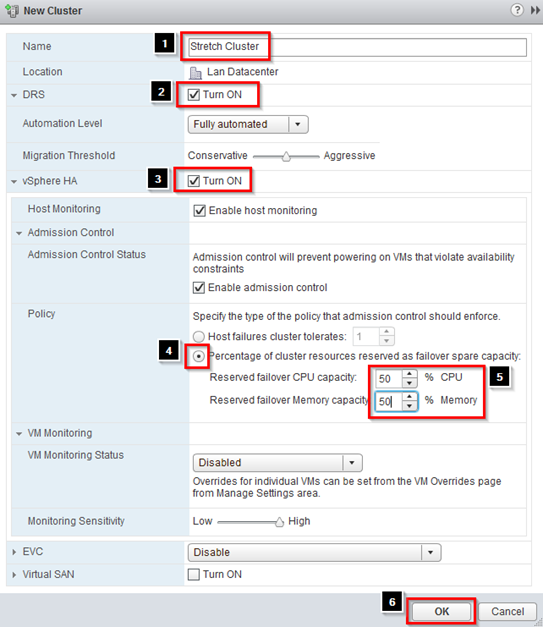
- Enter a Name for the cluster
- Check Turn ON next to DRS
- Check Turn ON next to vSphere HA
-
Under policy change the Percentage of cluster resources reserved as failover spare capacity
- Set Reserved failover CPU capacity to 50%;
- Set Reserved failover Memory Capacity to 50%
- Click on OK
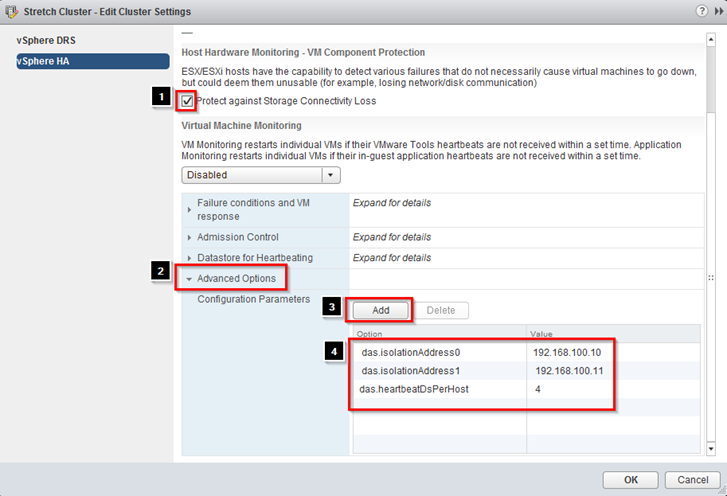
vSphere HA Advance Settings
In these next steps, one of these addresses physically resides in the Site A data center; the other physically resides in Site B data center. This enables vSphere HA validation for complete network isolation, even in case of a connection failure between sites. In the next few steps we are going to configure multiple isolation addresses. The vSphere HA advanced setting used is das.isolationaddress. More details on how to configure this can be found in VMware Knowledge Base article 1002117.
The minimum number of heartbeat datastores is two and the maximum is five. For vSphere HA datastore heartbeating to function correctly in any type of failure scenario, VMware recommends increasing the number of heartbeat datastores from two to four in a stretched cluster environment. This provides full redundancy for both data center locations. Defining four specific datastores as preferred heartbeat datastores is also recommended, selecting two from one site and two from the other. This enables vSphere HA to heartbeat to a datastore even in the case of a connection failure between sites. Subsequently, it enables vSphere HA to determine the state of a host in any scenario.
Adding an advanced setting called das.heartbeatDsPerHost can increase the number of heartbeat datastores.
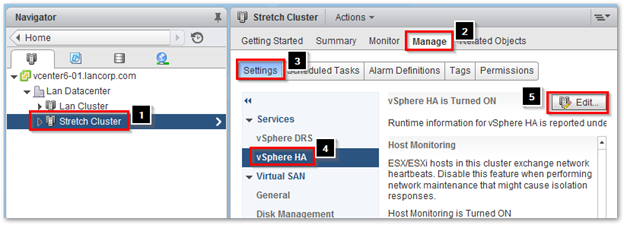
- Select your Cluster and click on Manager > Settings > vSphere HA > Edit
-
Configure vSphere HA advance settings
- Check the box Protect against Storage Connectivity Loss
- Click on dropdown next to Advanced Options
- Click on Add
-
Add the following values
- Enter das.isolationaddress0= (Additional pingable IP address for Site A)
- Enter das.isolationaddress1= (Additional pingable IP address for Site B)
- das.heartbeatDSPerHost = 4
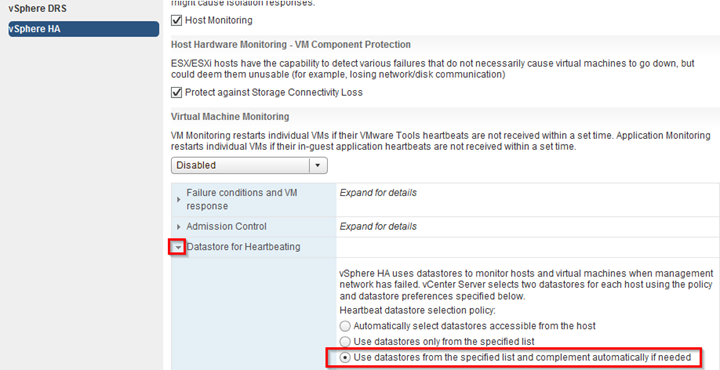
Datastore Heartbeating
To designate specific datastores as heartbeat devices, VMware recommends using Select any of the cluster datastores taking into account my preferences. This enables vSphere HA to select any other datastore if the four designated datastores that have been manually selected become unavailable. VMware recommends selecting two datastores in each location to ensure that datastores are available at each site in the case of a site partition.
- Expand Datastore for Heartbeating and select Use datastores from the specified list and complement automatically if needed
Permanent Device Loss and All Paths Down Scenarios
As of vSphere 6.0, enhancements have been introduced to enable an automated failover of VMs residing on a datastore that has either an all paths down (APD) or a permanent device loss (PDL) condition. PDL is applicable only to block storage devices.
A PDL condition, as is discussed in one of our failure scenarios, is a condition that is communicated by the array controller to the ESXi host via a SCSI sense code. This condition indicates that a device (LUN) has become unavailable and is likely permanently unavailable. An example scenario in which this condition is communicated by the array is when a LUN is set offline. This condition is used in nonuniform models during a failure scenario to ensure that the ESXi host takes appropriate action when access to a LUN is revoked. When a full storage failure occurs, it is impossible to generate the PDL condition because there is no communication possible between the array and the ESXi host. This state is identified by the ESXi host as an APD condition. Another example of an APD condition is where the storage network has failed completely. In this scenario, the ESXi host also does not detect what has happened with the storage and declares an APD.
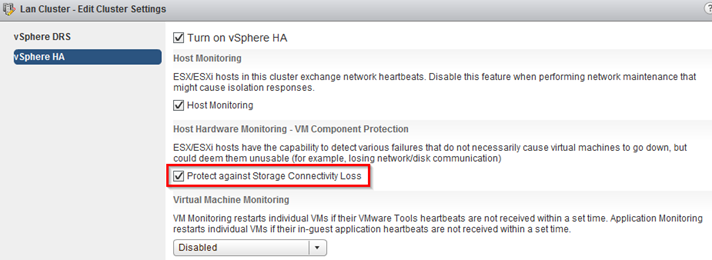
To enable vSphere HA to respond to both an APD and a PDL condition, vSphere HA must be configured in a specific way. VMware recommends enabling VM Component Protection (VMCP). After the creation of the cluster, VMCP must be enabled
- Under Host Hardware Monitoring – VM Component Protection, check the box next to Protect against Storage Connectivity Loss
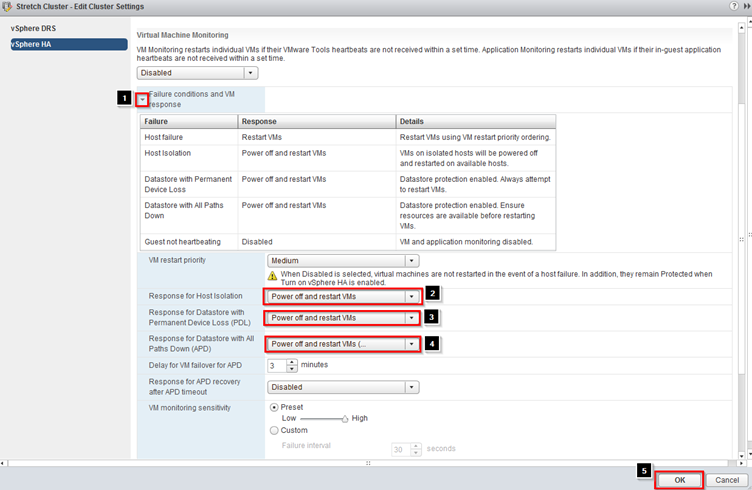
Permanent Device Loss (PDL) and All Paths Down (ADP) Settings
The configuration for Permanent Device Loss (PDL) is basic. In the Failure conditions and VM response section, the response following detection of a PDL condition can be configured. VMware recommends setting this to Power off and restart VMs. When this condition is detected, a VM is restarted instantly on a healthy host within the vSphere HA cluster.
For an APD scenario, configuration must occur in the same section, as is shown in Figure 8. Besides defining the response to an APD condition, it is also possible to alter the timing and to configure the behavior when the failure is restored before the APD timeout has passed.
When an APD condition is detected, a timer is started. After 140 seconds, the APD condition is officially declared and the device is marked as APD timeout. When 140 seconds have passed, vSphere HA starts counting. The default vSphere HA timeout is 3 minutes. When the 3 minutes have passed, vSphere HA restarts the impacted VMs, but VMCP can be configured to respond differently if preferred. VMware recommends configuring it to Power off and restart VMs (conservative).
Conservative refers to the likelihood that vSphere HA will be able to restart VMs. When set to conservative, vSphere HA restarts only the VM that is impacted by the APD if it detects that a host in the cluster can access the datastore on which the VM resides. In the case of aggressive, vSphere HA attempts to restart the VM even if it doesn’t detect the state of the other hosts. This can lead to a situation in which a VM is not restarted because there is no host that has access to the datastore on which the VM is located.
If the APD is lifted and access to the storage is restored before the timeout has passed, vSphere HA does not unnecessarily restart the VM unless explicitly configured to do so. If a response is chosen even when the environment has recovered from the APD condition, Response for APD recovery after APD timeout
can be configured to Reset VMs. VMware recommends leaving this setting disabled.
-
Configure the following
- Click on the dropdown under Failure conditions and VM response
- Change the Response for Host Isolation to Power off and restart VMs
- Change the Response for Datastore with Permanent Device Loss (PDL) to Power Off and restart VMs
- Change the Response for Datastore with All Paths Down (APD) to Power Off and restart VMs (conservative)
Next we need to configure the Host settings, Groups, and Storage DRS settings
Good One, I have query like, to configure stretch cluster do we need vSAN ? or this can be configured on SAN storage ?
Vsan is not needed. Make sure you find the latest documentation for this